Existing approaches face a fundamental trade-off:
- Imitation learning (IL): Realistic and human-like, but tokenized or diffusion models are large (GPU memory heavy), slow, and difficult to scale.
- Self-play reinforcement learning (RL): Efficient and scalable, but requires reward shaping and often diverges from human norms.
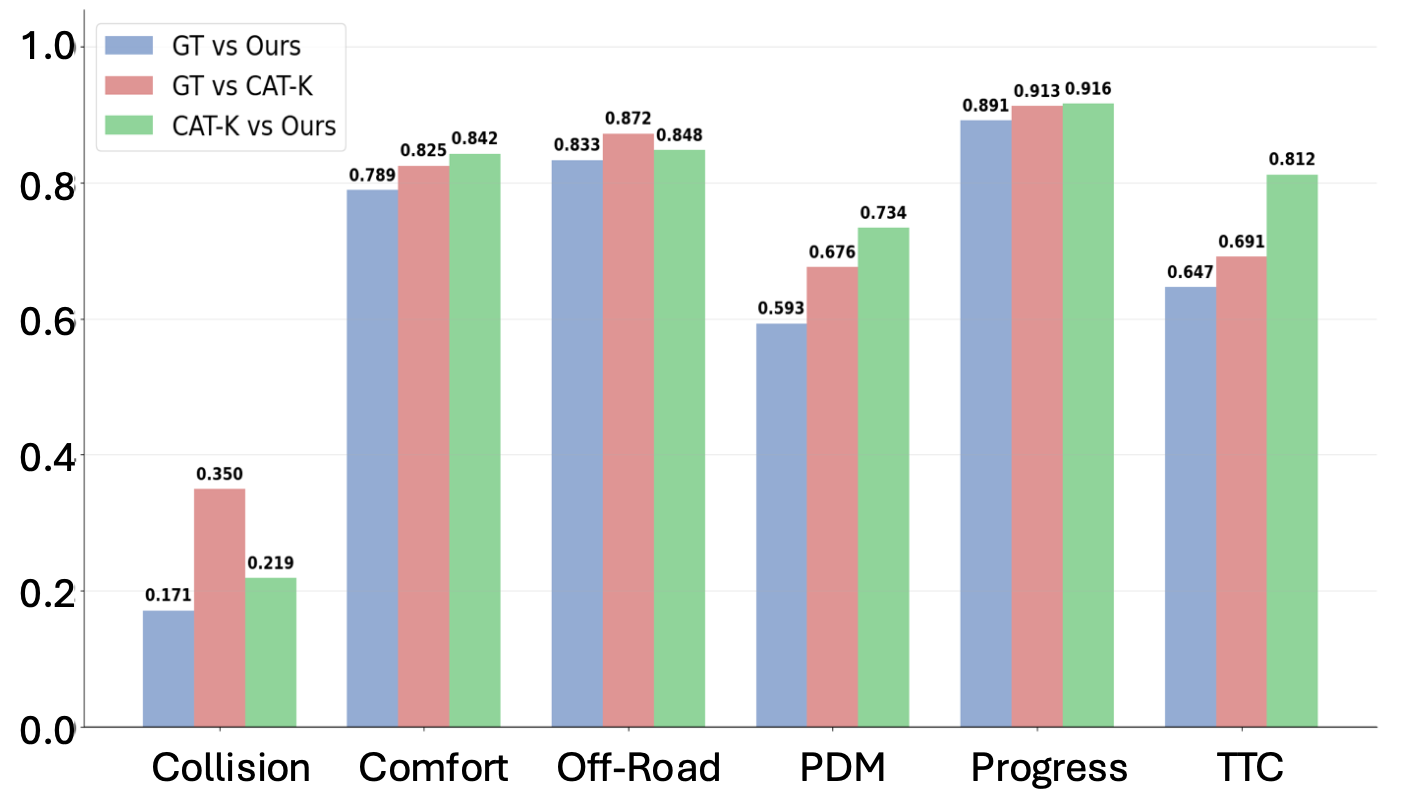
SPACeR is an RL-first approach designed to bridge these gaps—combining the scalability of self-play with the realism of IL. Our policies are ~50× smaller than tokenized models and run 10× faster (or more!), enabling lightweight, human-like multi-agent simulation.
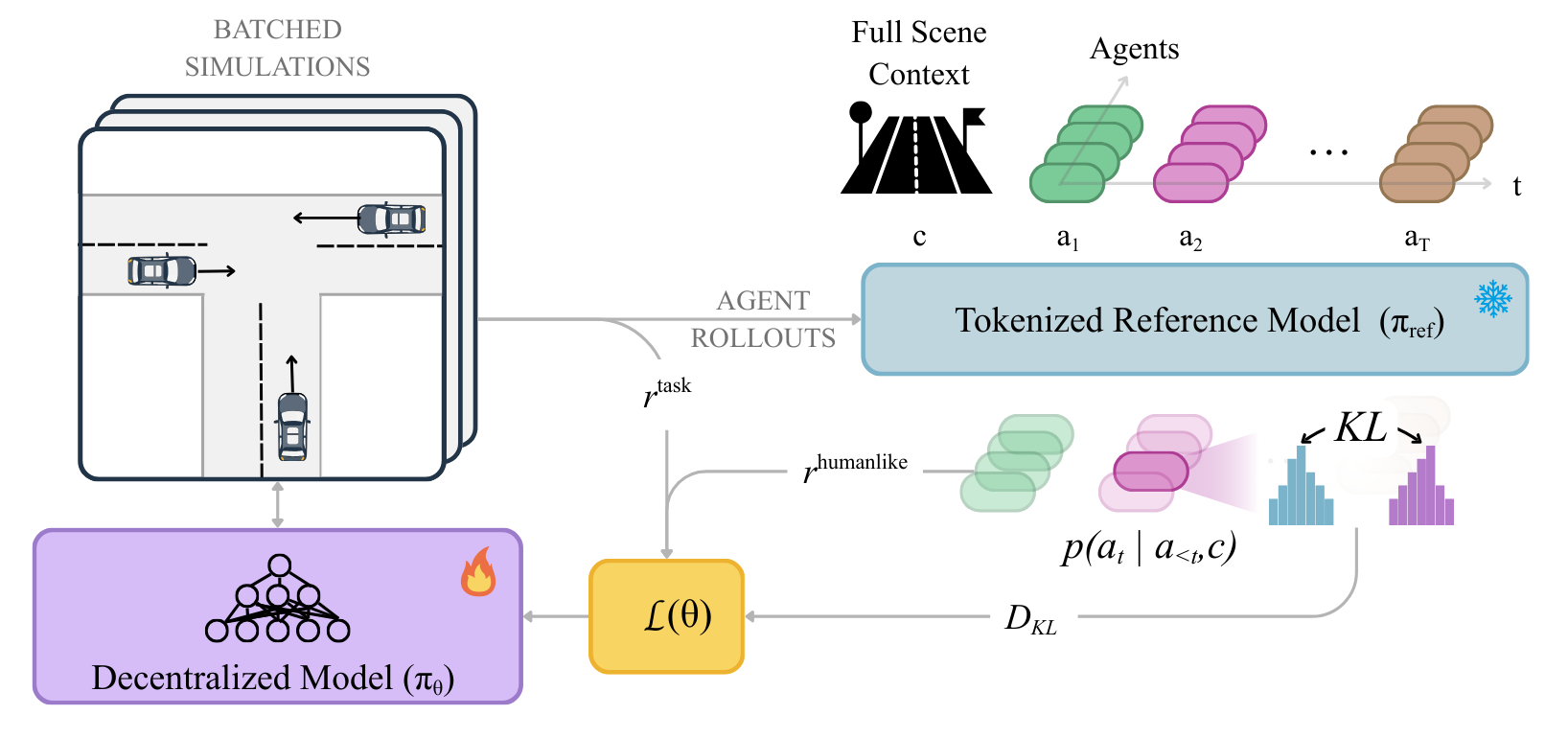
We propose to anchor self-play reinforcement learning to a pretrained tokenized reference model, which provides a human-likeness distributional signal. The resulting SPACeR policy is decentralized and conditioned only on local observations, while the reference model is centralized and conditioned on the full scene context—allowing scalable training without sacrificing realism.